0%
最小堆与最大堆
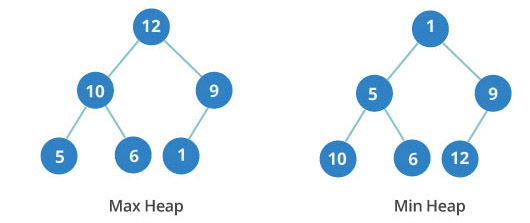
- 堆是一种经过排序的完全二叉树,对其中任一非终端节点,其数据值不大于(或不小于)其左右子节点的值。
- 最小堆(最大堆)堆能保证堆顶元素最小(最大),相比于用数组存放数据,如果要查找所有数据中最小(最大)的数据时,数组的时间复杂度为O(n),而最小堆(最大堆)的时间复杂度为O(1)。
- 而数据增删数据时,需要保证最小堆(最大堆)的动态可维护性仅需O(logN)。因此在特定的需求环境,最小堆(最大堆)这种数据结构非常高效。

Manjaro系统安装.rpm或.deb软件
尽管AUR被称为这个星球上最大的软件资源库,但不可避免的,我们有时会遇到在AUR库中没有待装软件,而待装软件官网只提供.rpm或.deb软件包的情况。本文将介绍如何利用.rpm或.deb软件包资源创建一个Arch软件包,然后在Manjaro系统下安装这些软件。

高效软件推荐

1. 浏览器
1.1. chrome/Microsoft Edge
第三方搜集的Google官方离线包,Google Chrome下载地址:https://api.shuax.com/tools/getchrome